- Authors

- Name
- Youngju Kim
- @fjvbn20031
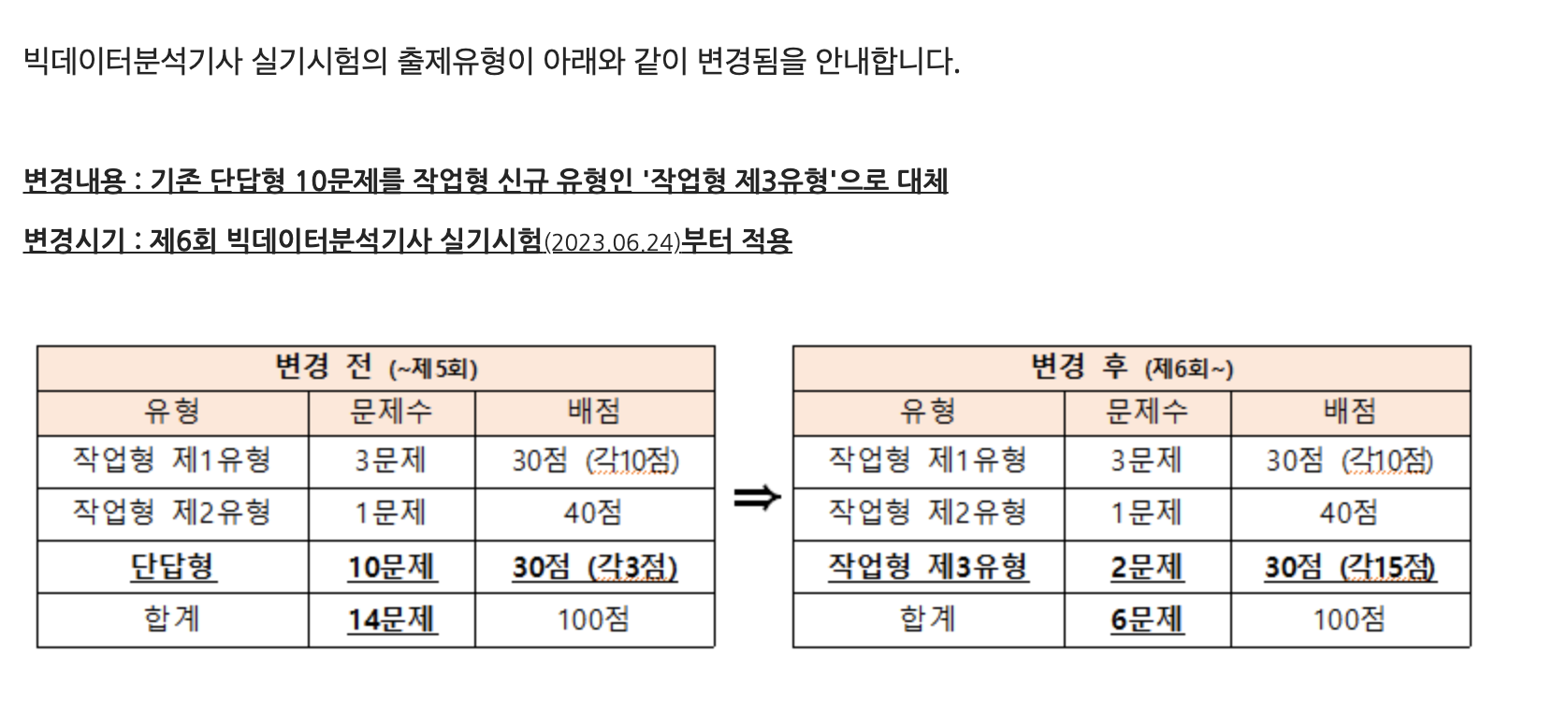
2023년 6월 24일 치뤄질 빅데이터 분석기사 6회 실기시험을 준비하며 공부한 내용들을 정리하려고 합니다. 이번 6회 시험에서는 기존에 있던 단답형 문항들이 삭제되고 작업형 3유형이 추가되었습니다. 머신러닝을 손에서 놓은지 2년이 다 되어가기 때문에 정리를 한번 하려고 합니다. 1유형과 2유형은 패턴이 이미 정해져 있어 크게 어렵지 않을 것으로 보이지만, 3 유형은 통계적인 지식도 함께 물어보기 때문에 난이도가 있을 것으로 보입니다.
실기 시험 준비는 퇴근후딴짓 님의 유튜브의 영상들과, 이 분이 관리하시는 케글 페이지에 올라와있는 기출 문제 복원 문제들을 많이 참고하였고 도움을 많이 얻었습니다.
작업형 1유형
데이터 기초 조작 능력을 물어보기 때문에 다른 유형들에 비해 상대적으로 쉽지만, IDE가 제공되지 않기 때문에 라이브러리 사용법이나, DataFrame 문법은 한번 정리하고 넘어가 필요가 있을 것 같아, 기존 기출 시험에서 필요했던 명령어를 정리해봅니다.
# csv 데이터 읽어들일 때
import pandas as pd
train = pd.read_csv("data/train .csv")
# 데이터 기초 통계자료 확인
train.head() # 일부 데이터만 확인할 때
train.describe() # 평균, 표준편차, 사분위값 확인
train.describe(include="object") # 명목형(Categorical) 변수에 대한 기초 데이터 확인 (이 때 train에 명목형 변수의 unique 값과 test의 명목형 변수의 unique 값이 동일한지 확인해보아야 함. 만약 다르다면 Label Encoding 작업시 train, test 데이터 합쳐서 encoding 진행해야 함.)
train.isnull().sum() # 결측치 확인
# minmax scaler 직접 구현
def minmax(data):
data = (data-min(data))/(max(data)- min(data))
return data
# qsec 수치형 변수에 대해 minmax scaler를 적용한다고 했을 때,
train['qsec'] = minmax(train['qsec'])
# sklearn minmax scaler 이용
from sklearn.preprocessing import minmax_scale
qsec_scaled = minmax_scale(train['scale'])
# 'qsec'이 0.5이상인 row의 개수
sum(qsec_scaled >0.5) # True의 수의 합
len(train[qsec_scaled >0.5]) #data의 길이의 합
# age 컬럼의 표준편차 구하기
age_std = train['age'].std()
# f1 컬럼 결측치 중앙값으로 보간
train['f1'] = train['f1'].fillna(train['f1'].median())
# 앞에서 70%의 데이터만 활용하기
df = df.iloc[:int(len(df)*0.7),:]
# 컬럼 filter 조건 여러개
# age 컬럼의 이상치의 합.평균으로부터 '표준편차 * 1.5'를 벗어나는 영역을 이상치라고 판단.
age = train['age']
age_outliers = age[ ((age < age.mean()-age.std()*1.5) | (age > age.mean()+age.std()*1.5))]
age_outliers.sum()
# index 기반 sort
train.sort_index(ascending=True) # 오름차순
train.sort_index(ascending=False) # 내림차순
# value 기반 sort. age 기준으로 내림차순 정렬
sorted_train = train.sort_values(by=['age'], ascending=False)
# data frame을 iloc으로 접근하기.
# 시작 row부터 10개의 row에 마지막 컬럼을 10개의 row중 'f5' 컬럼의 최솟값으로 업데이트
df.iloc[:10, -1] = df['f5'][:10].min()
# age 컬럼의 3사분위 수와 1사분위의 차를 절대값으로 구하고, 소수점 버려서 정수로 출력
ans = int(abs(df['age'].quantile(0.25) - df['age'].quantile(0.75)))
# 컬럼의 타입 변경
submission['Segmentation'] = submission['Segmentation'].astype(int)
작업형 2 유형
작업형 2 유형은 supervised learning이 나오고. Classification 또는 Regression Task가 출제된다. 약간 귀찮은 점은 Feature에 수치형(Numerical) 변수와 명목형(Categorical) 변수가 혼합되어있어 이를 전처리에서 적절하게 하고 모델을 학습시키는 것이 핵심이다. 성능을 높이기 위해서는 Hyper Parameter 튜닝이나 이상치나 결측치 처리를 해주는 작업을 해주면 된다. (시간이 많을 때 옵션인 것 같다). 결과물 제출시 명시된 format 대로 잘 맞춰서 제출하는 것이 중요하다. 수치형 변수에 대한 scaling이 필요하지 않고 성능도 준수한 트리기반 Model(RandomForest)을 선택하는 것이 시간절약에 유리할 것으로 보인다.
작업형 2 유형을 해결하는 전체적인 task는 아래와 같다.
- 데이터 EDA(변수 type 확인, 기초통계량 확인, 이상치나 결측치 확인, target 변수 확인)
- 데이터 전처리(명목형 변수 인코딩, 결측치 처리, train/valid 데이터셋 분리)
- 모델 생성 및 학습/평가.
- test 데이터 답 제출
# EDA
import pandas as pd
# 데이터 읽기
df = pd.read_csv("train.csv")
# 데이터 차원 확인
print(df.shape)
# 결측치 확인
print(df.isnull().sum())
# 기초 통계량 확인
print(df.describe())
# 데이터 전처리
df['age'] = df['age'].fillna(df['age'].median())
# 데이터에서 target column 추출
target = df.pop('target')
# Label Encoding (범주형 변수 레이블 인코딩)
from sklearn.preprocessing import LabelEncoder
cols = df['aa', 'bb'] # 범주형 변수
for col in cols:
le = LabelEncoder()
df[col] = le.fit_transform(df[col])
X_test[col] = le.transform(X_test[col])
print(df.head())
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(df, target)
print(model.score(df, target))
predictions = model.predict_proba(X_test)
# score 처리 지표 확실하게 알아두기.
작업형 3 유형
작업형 3유형의 경우, 어떤 문제가 나올지 예상이 안되어 리서치를 했는데, 유튜브에 슬기로운통계생활 님께서 올려주신 영상을 바탕으로 아래와 같은 통계 지표를 python으로 구현하는 방법을 암기해가려고 한다.
- Z검정
- T검정
- 1표본
- 2표본
- 두 그룹의 분산이 같은 경우
- 두 그룹의 분산이 다른 경우
- paired t 검정
- 카이제곱검정
- ANOVA
import pandas as pd
from scipy import stats
a = pd.read_csv('data/blood_pressure.csv', index_col=0)
# print(a.shape)
# print(a.head())
a['diff'] = a['bp_after'] - a['bp_before']
#1
print(round(a['diff'].mean(),2))
#2
st , pv = stats.ttest_rel(a['bp_after'], a['bp_before'], alternative='less')
print(round(st,4))
#3
print(round(pv,4))