- Authors

- Name
- Youngju Kim
- @fjvbn20031
Background
HBase는 Hadoop위에서 동작하는 RealTime DataBase지만 Relational DB처럼 고수준의 DML을 제공하지는 않는다. NoSQL이라고 하더라도 성능과, 확장성에 초점을 맞춘 나머지 정말 간단한 API만을 개발자에게 제공한다. PUT, GET, SCAN, DELETE, INCREMENT 와 그에 파생된 몇가지 연산이 전부이다. Relational DB에서 많이 사용되는 Secondary Index나, JOIN은 제공되지 않을 뿐 아니라 Transaction도 row 단위만 제공한다. 따라서 row-key라고 불리우는 유일한 key를 한번 잘못 설계하면 데이터를 조회하거나 집계할 때, 테이블 전체를 뒤지는 (Full Scan)을 실행해야하는 수고를 들여야할 수 있다. Full Scan을 위해서 병렬처리 하는 것도 쉽지 않다. Single Thread로 실행할 경우 데이터 크기가 작다면, full scan도 상관없지만, 데이터 크기가 TB 수준까지 올라가는 경우 몇 일이 걸릴 수 도 있다. 좋은 방법이 아니다.
다행히도 이 Full Scan을 빠르게 할 방법이 있다. 바로 Mapreduce를 사용하는 것이다. HBase는, Hadoop의 Mapreduce의 Data Source로서 사용될 수 있다. Mapreduce는 예전 기술이긴 하지만, Batch 처리용으로 사용되는데에는 문제가 없고 HBase 공식 document 에서도 HBase와 Mapreduce 연동 방법을 안내한다.
Goal
Mapreduce 프로그램 중 가장 간단한, Table Row 수를 계산하는프로그램을 만들어 본다.
Steps
HBase Cluster
당연하게도, HBase Cluster가 있어야한다. 또한 Mapreduce 작업을 실행하기 위한 YARN 컴포넌트도 있어야한다. HBase 설치방법은 이쪽을 참고한다.
현재 클러스터는 master node 1대, worker node 3대로 구성되어있다.
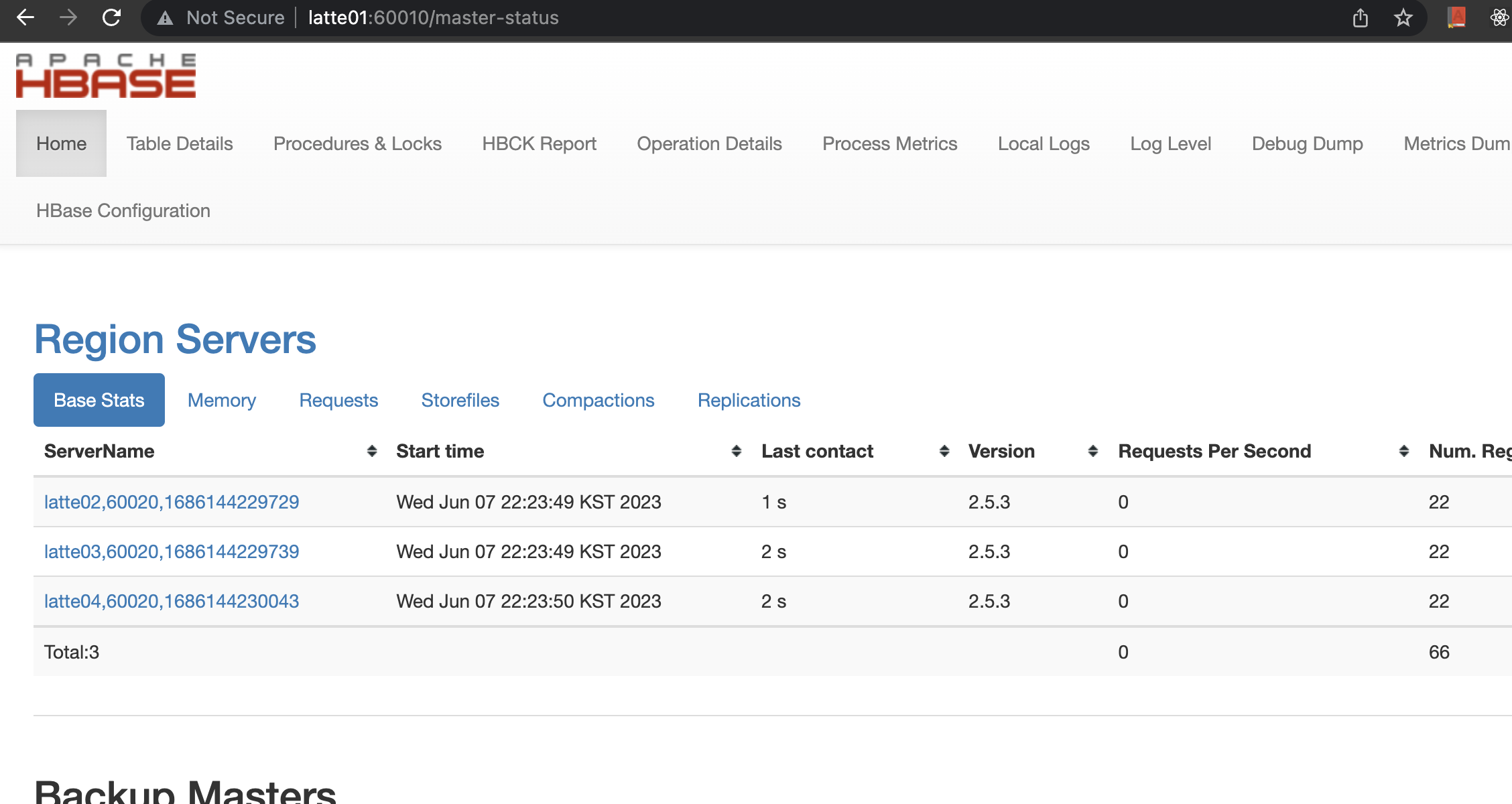
개발 환경 구축
Intellij에서 new project를 통해
Map Reduce Program 작성
MapReduce Program을 만들기 위해서는 일반적으로 Driver, Mapper, Reducer 세가지가 필요한데, Row Counter program의 경우 Reducer가 필요 없기 때문에 Driver와 Mapper만 작성한다.
Driver 함수 작성
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.output.NullOutputFormat;
import java.io.IOException;
public class RowCounterJob {
private static final String zookeeper_quorum = "latte01,latte02,latte03";
private static final String zookeeper_port = "2181";
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// HBase 관련 config 등록
Configuration config = HBaseConfiguration.create();
config.set("hbase.zookeeper.quorum", zookeeper_quorum);
config.set("hbase.zookeeper.property.clientPort", zookeeper_port);
// Job 생성
Job job = new Job(config, "RowCounter");
job.setJarByClass(RowCounterJob.class);
Scan scan = new Scan();
// Full Scan을 할 때, scan 객체를 아래처럼 설정해주어야 한다.
scan.setCaching(500);
scan.setCacheBlocks(false);
// Table Mapper 등록
TableMapReduceUtil.initTableMapperJob(
"usertable", // table 명
scan,
RowCounterMapper.class, // Mapper Class 등록
Text.class,
IntWritable.class,
job
);
job.setOutputFormatClass(NullOutputFormat.class);
job.setNumReduceTasks(1);
// job 제출
boolean b = job.waitForCompletion(true);
if(!b){
throw new IOException("error with job");
}
}
}
Mapper 함수 작성
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.io.ImmutableBytesWritable;
import org.apache.hadoop.hbase.mapreduce.TableMapper;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class RowCounterMapper extends TableMapper<Text, IntWritable> {
public enum Counters {ROWS}
@Override
protected void map(ImmutableBytesWritable key, Result value, Mapper<ImmutableBytesWritable, Result, Text, IntWritable>.Context context) throws IOException, InterruptedException {
context.getCounter(Counters.ROWS).increment(1);
}
}
필요한 라이브러리
현재 구축한 Hadoop과 HBase 버젼을 확인한다.
HBase: 2.5.3 Hadoop: 3.3.2
hbase version에 따라 필요한 라이브러리 명이 다르다.
hbase-client 와 hbase-mapreduce 가 필요하다.
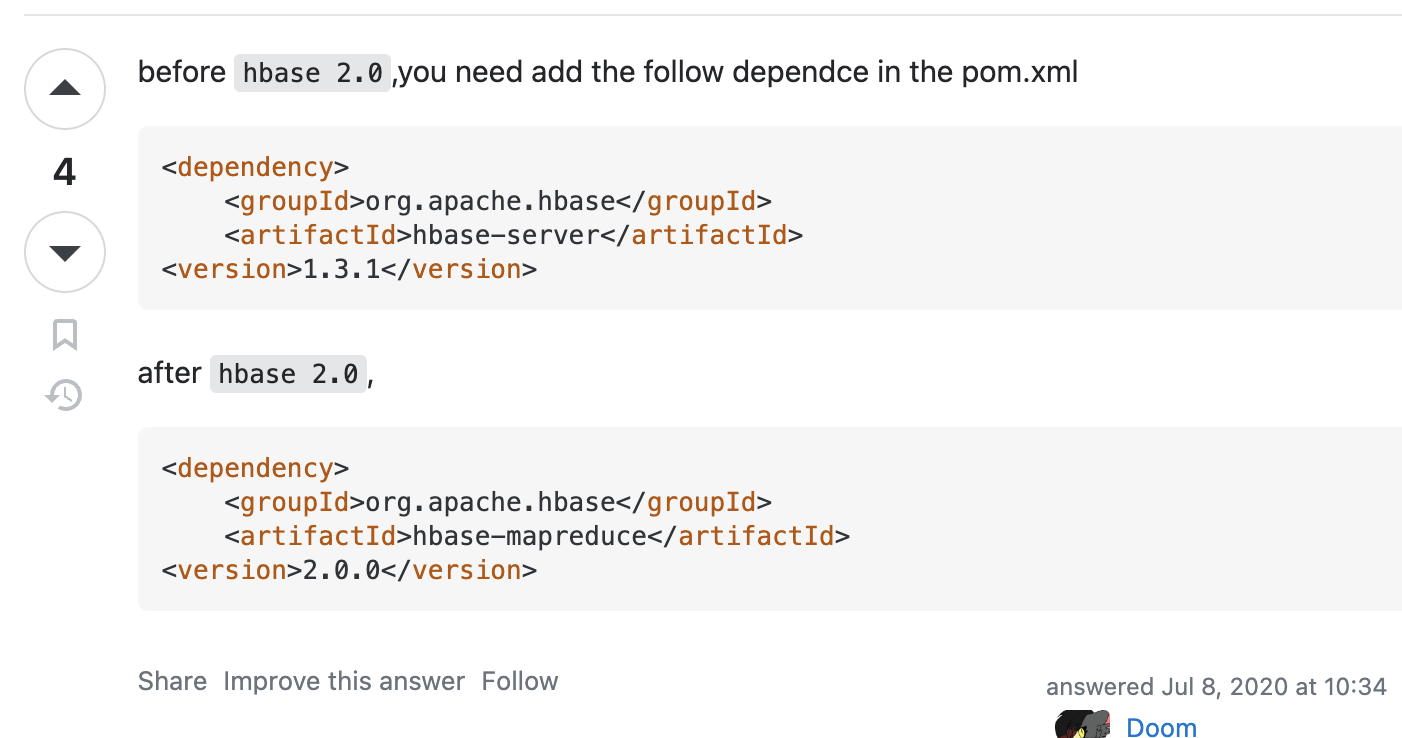
<dependencies>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.5.3</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>2.5.3</version>
</dependency>
</dependencies>
Mapreduce jar build 및 생성 방법
mapreduce Job을 실행하기 위해 필요한 모든 dependency들이 포함된 하나의 jar파일로 생성해야한다.
maven의 maven-assembly-plugin을 사용해도 되지만, 편의상 Intellij에서 제공하는 Artifacts의 기능을 사용한다.
좌측 상단에 File -> Project Structure -> Artifacts -> ADD -> JAR -> From Modules with dependencies 클릭
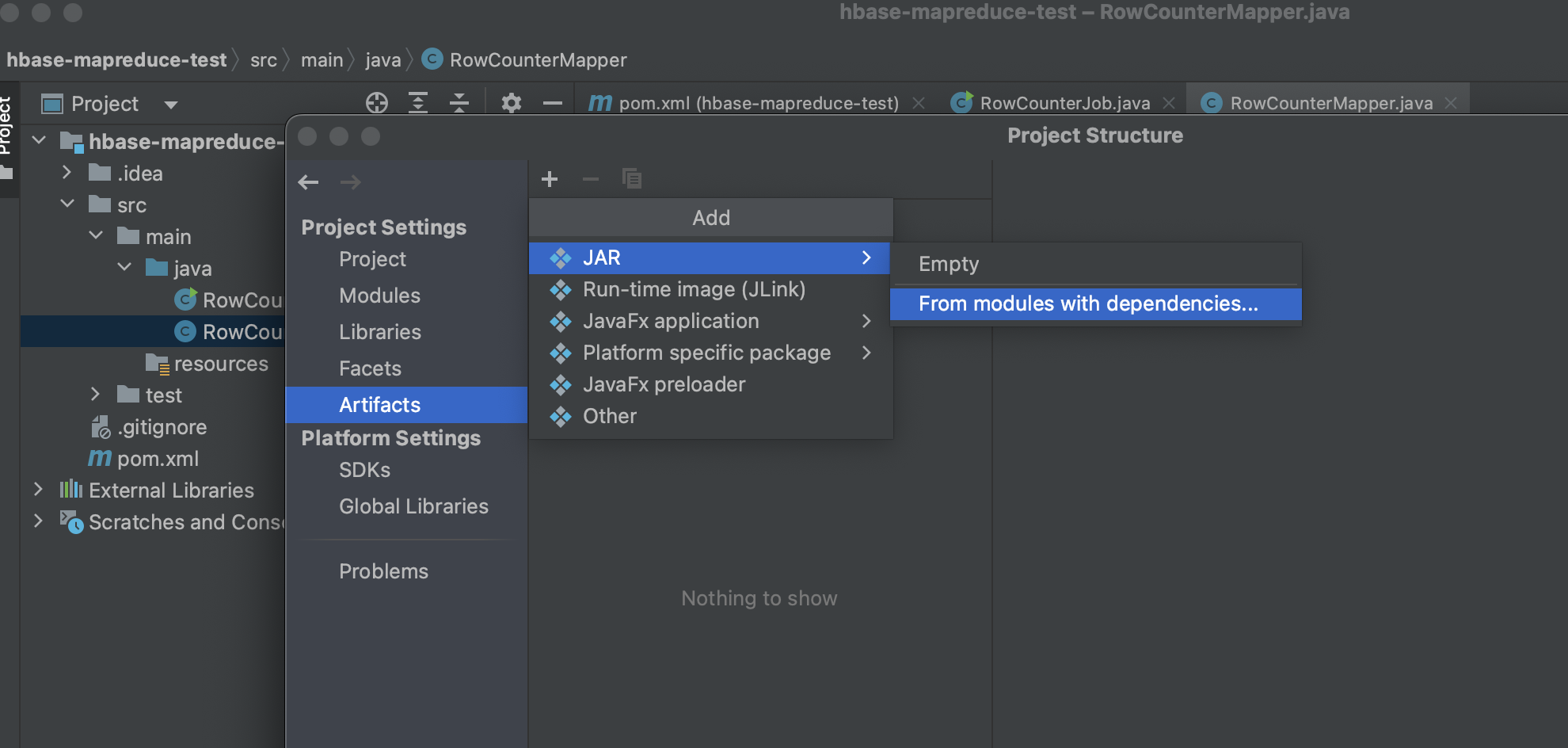
그리고 나서, Main Class를 찾아주고 extract to the target JAR를 선택하여 새로운 artifact를 생성한다.
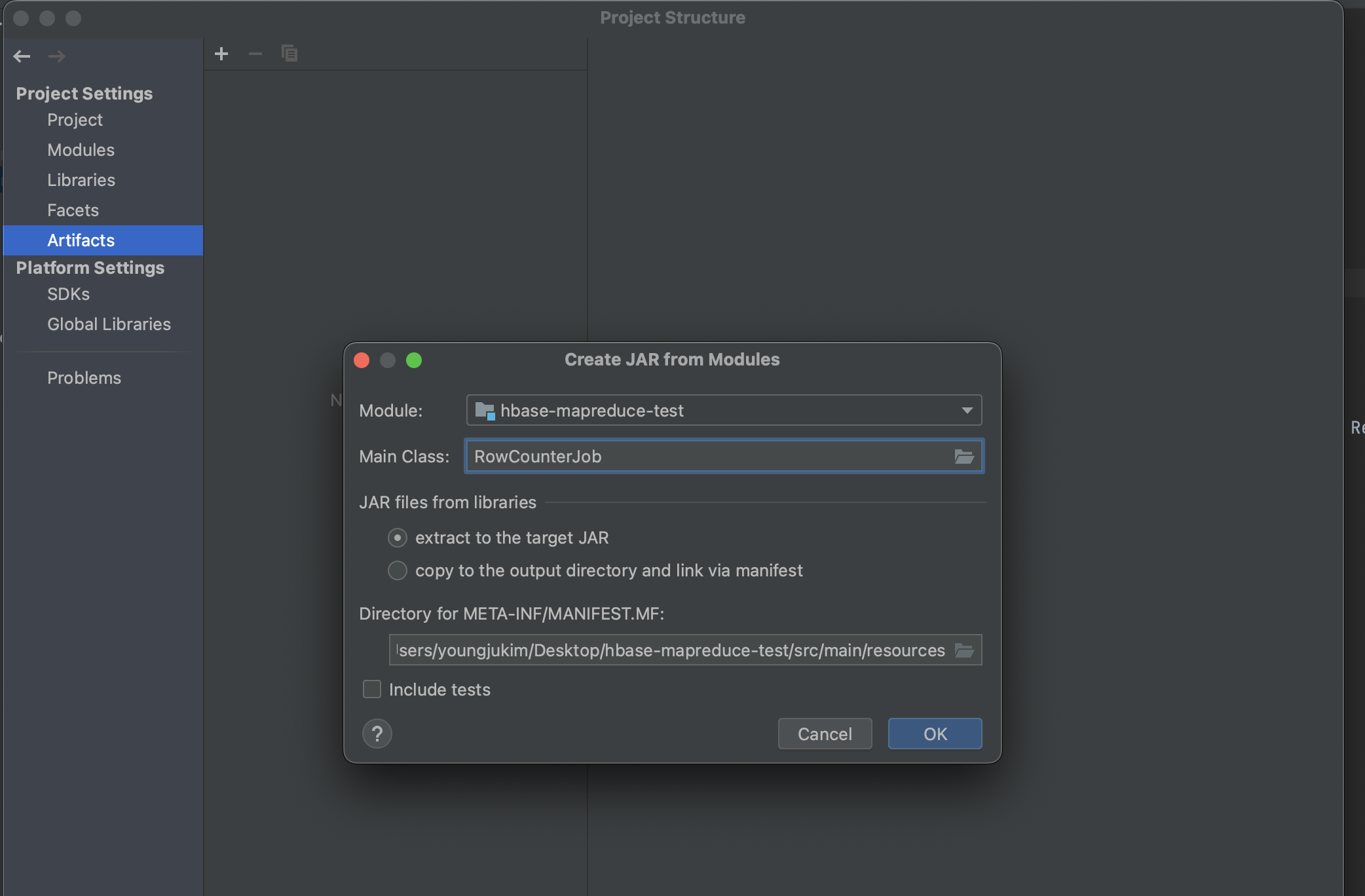
상단에 Build -> Build Artifact를 눌러 build를 진행한다.
프로젝트 루트 디렉터리에서 Out -> artifacts -> 하위에 들어가 보면 jar 파일이 생성된 것을 확인할 수 있다.
jar 파일 실행 방법
해당 파일을 hbase와 yarn을 실행할 수 있는 서버로 옮긴다. 필자는 Local PC의 public key를 latte01의 authorized_keys에 등록해두었기 때문에 아래와 같은 scp 명령어를 사용해 파일을 전송할 수 있었다.
scp hbase-mapreduce-test.jar latte01:<path you want to move>
mapreduce Job 제출 방법.
HADOOP_CLASSPATH=`hbase classpath` hadoop jar hbase-mapreduce-test.jar RowCounterJob
위의 명령어로 실행했을 때 아래와 같은 애러 메시지가 발생하여 job이 제출되지 않았다.
Exception in thread "main" java.lang.IllegalAccessError: class org.apache.hadoop.hdfs.web.HftpFileSystem cannot access its superinterface org.apache.hadoop.hdfs.web.TokenAspect$TokenManagementDelegator
https://stackoverflow.com/questions/62880009/error-through-remote-spark-job-java-lang-illegalaccesserror-class-org-apache-h 에 따르면, fat jar를 만들 때 hadoop-hdfs Library가 문제를 일으키는 것 같아 artifact 생성시 해당 library를 remove 하였다.
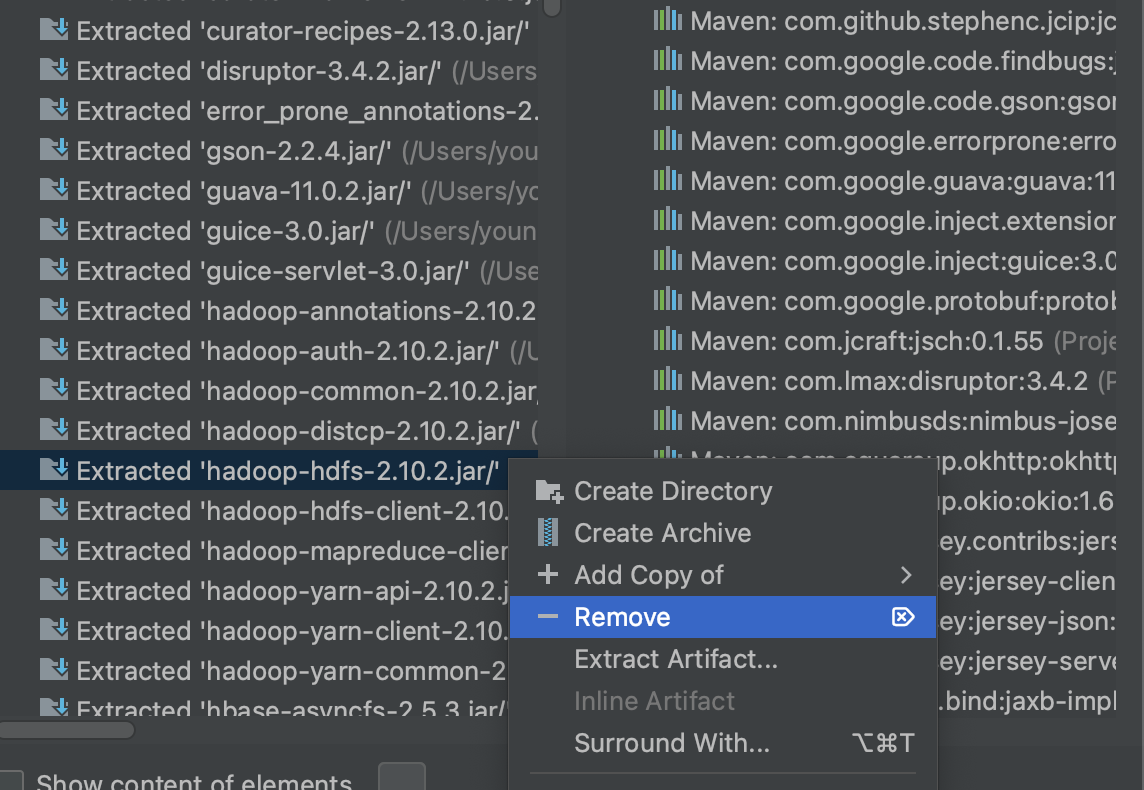
같은 애러 발생하여, hbase 에서 기본적으로 들어있는 row counter는 정상적으로 동작하는지 확인해보았다.
hbase org.apache.hadoop.hbase.mapreduce.RowCounter <table name>
애초에 YARN cluster에 문제가 있었던 것으로 보인다.
hdfs 상에 /user/hdfs, /user/hbase, /user/root 디렉터리를 생성한다.
hdfs dfs -mkdir /user
hdfs dfs -mkdir /user/hdfs
hdfs dfs -mkdir /user/hbase
hdfs dfs -mkdir /user/root
hdfs dfs -chown hbase:supergroup /user/hbase
hdfs dfs -chown hdfs:supergroup /user/hdfs
user directory를 생성했음에도, 아래와 같은 애러가 발생했다.
023-06-10 16:11:13,539 ERROR [main] org.apache.hadoop.mapreduce.v2.app.MRAppMaster: Error starting MRAppMaster
java.lang.ClassCastException: org.apache.hadoop.hdfs.protocol.proto.ClientNamenodeProtocolProtos$GetFileInfoRequestProto cannot be cast to com.google.protobuf.Message
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:232)
https://ngela.tistory.com/66 에 따르면 hadoop version에 따른 protobuf가 달라지면서 생기는 문제라고한다.
hadoop 과 hbase를 버전에 맞도록 다시 설치하고 다시 시도해본다.
HBase: 2.5.3 Hadoop: 2.10.2 Zookeeper: 3.5.7
hadoop 2.10.2 재설치시 config
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://latte01:9000</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///dfs/nn</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///dfs/dn</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:///dfs/sn</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:9870</value>
</property>
</configuration>
export HADOOP_IDENT_STRING=$USER
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HDFS_NAMENODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_DATANODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>latte01:8025</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>latte01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>latte01:8040</value>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>file:///dfs/yarn/local</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>file:///dfs/yarn/logs</value>
</property>
</configuration>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/hadoop</value>
</property>
</configuration>
latte02
latte03
latte04
namenode format 후 HDFS 실행.
namenode에서 아래 실행.
hadoop namenode -format
Hadoop, YARN component 실행
start-all.sh
Namenode와 Resource Manager가 정상적으로 실행된 것을 확인.
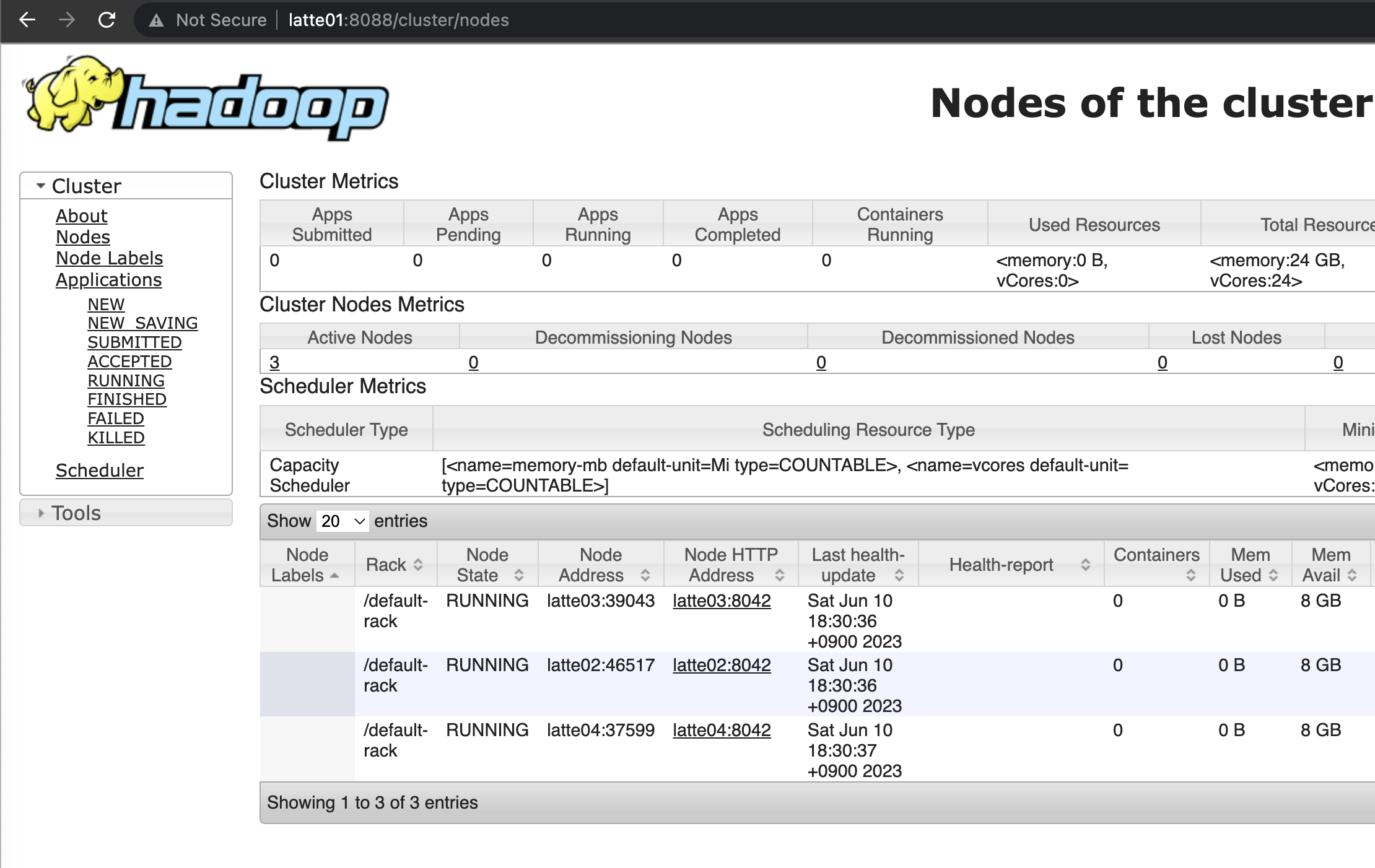
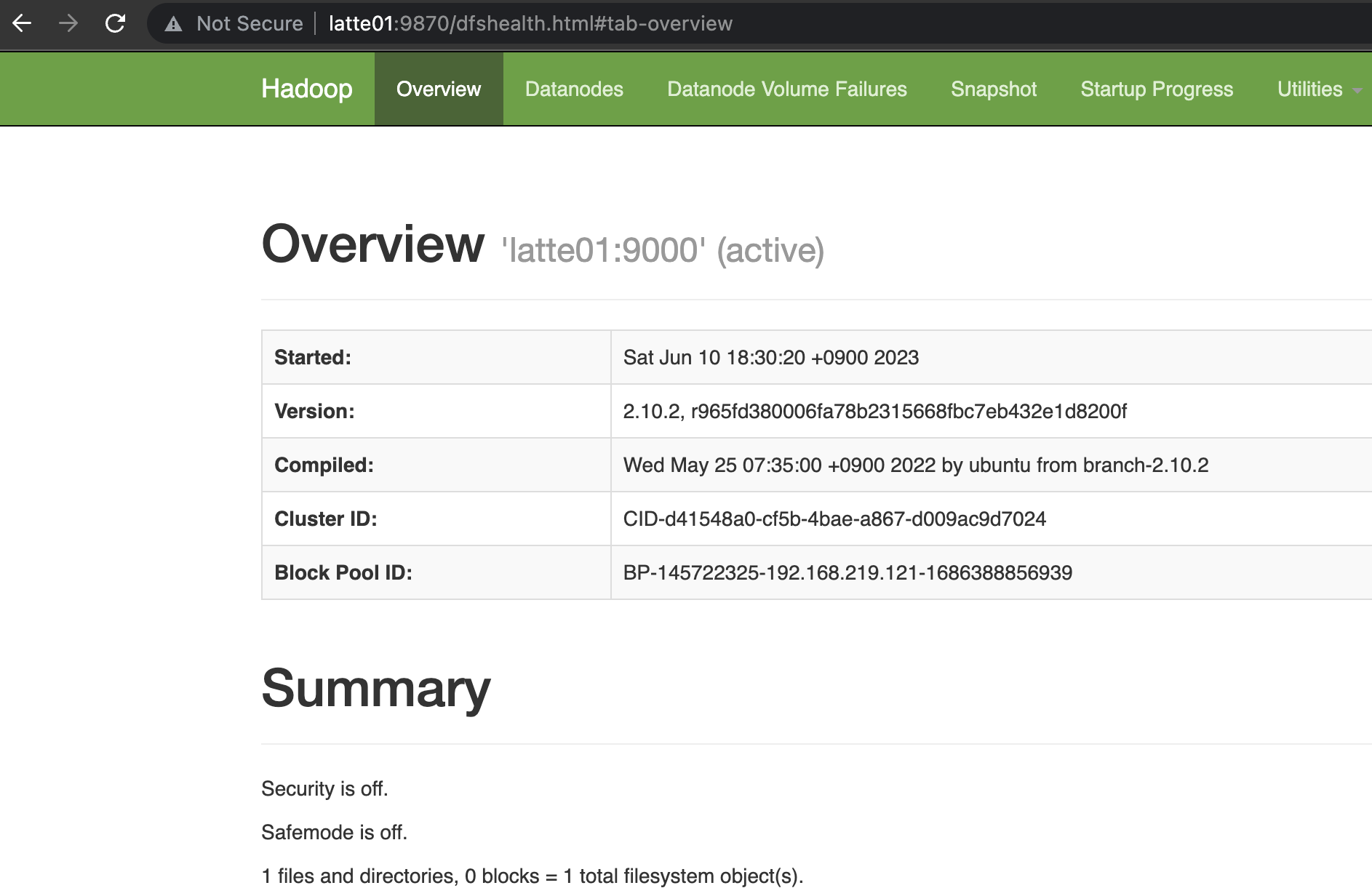
HBase 실행.
HBase 실행
start-hbase.sh
YCSB download 및 실행.
curl -O --location https://github.com/brianfrankcooper/YCSB/releases/download/0.17.0/ycsb-0.17.0.tar.gz
tar xfvz ycsb-0.17.0.tar.gz
cd ycsb-0.17.0
mkdir latte_hbase
vim hbase-site.xml
vim testoption
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://latte01:9000/hbase</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>hbase.master.port</name>
<value>60000</value>
</property>
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<property>
<name>hbase.regionserver.info.bindAddress</name>
<value>0.0.0.0</value>
</property>
<property>
<name>hbase.regionserver.port</name>
<value>60020</value>
</property>
<property>
<name>hbase.regionserver.info.port</name>
<value>60030</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>latte01,latte02,latte03</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
<property>
<name>hbase.backup.enable</name>
<value>true</value>
</property>
<property>
<name>hbase.master.logcleaner.plugins</name>
<value>org.apache.hadoop.hbase.backup.master.BackupLogCleaner</value>
</property>
</configuration>
recordcount=10000000
operationcount=1000000
hbase shell에 접속하여 usertable 생성
hbase(main):001:0> n_splits = 30
# HBase recommends (10 * number of regionservers)
hbase(main):002:0> create 'usertable', 'family', {SPLITS => (1..n_splits).map {|i| "user#{1000+i*(9999-1000)/n_splits}"}}
bin/ycsb load hbase20 -P workloads/workloada -P latte_hbase/testoptions -cp latte_hbase/ -p table=usertable -p columnfamily=family -p recordcount=10000000 -p operationcount=1000000 -threads 10
request 수가 1K가까이 증가한 것을 확인할 수 있다.
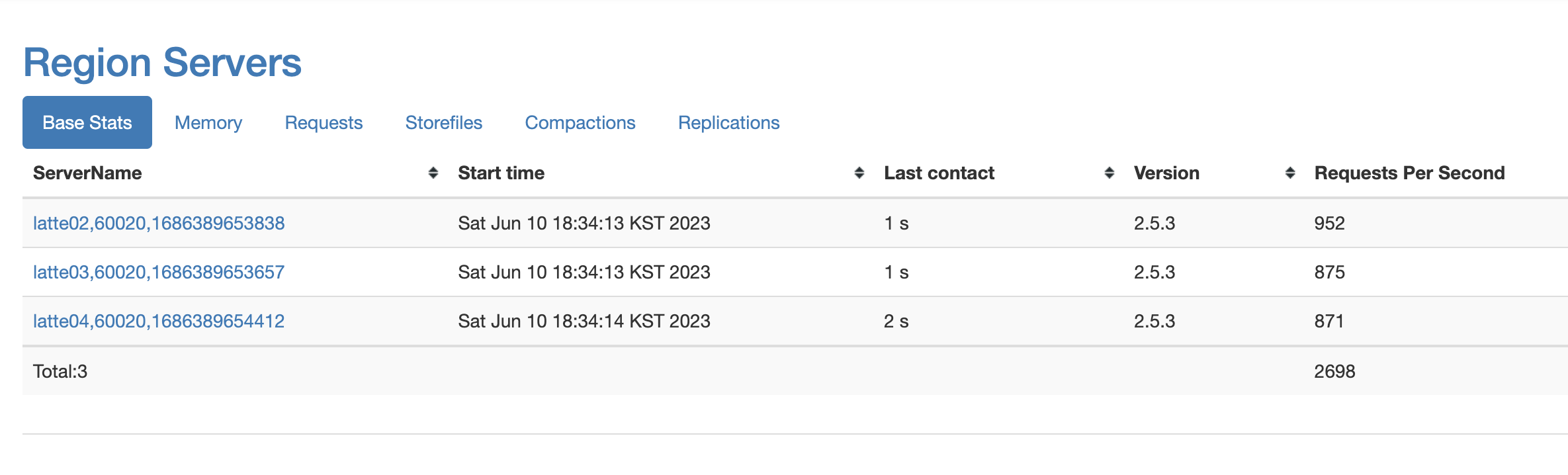
다시 Row Count Mapreduce를 실행해본다.
hbase org.apache.hadoop.hbase.mapreduce.RowCounter usertable
mapreduce job 정상 수행.
2023-06-10 19:13:18,891 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1643)) - Job job_1686391929383_0001 running in uber mode : false
2023-06-10 19:13:18,894 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 0% reduce 0%
2023-06-10 19:13:51,888 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 6% reduce 0%
2023-06-10 19:13:52,948 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 16% reduce 0%
2023-06-10 19:13:53,966 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 26% reduce 0%
2023-06-10 19:13:59,063 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 35% reduce 0%
2023-06-10 19:14:00,097 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 39% reduce 0%
2023-06-10 19:14:01,118 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1650)) - map 52% reduce 0%
HBaseCounters
BYTES_IN_REMOTE_RESULTS=14106802
BYTES_IN_RESULTS=59441193
MILLIS_BETWEEN_NEXTS=282081
NOT_SERVING_REGION_EXCEPTION=0
REGIONS_SCANNED=31
REMOTE_RPC_CALLS=22
REMOTE_RPC_RETRIES=0
ROWS_FILTERED=44
ROWS_SCANNED=374127
RPC_CALLS=88
RPC_RETRIES=0
org.apache.hadoop.hbase.mapreduce.RowCounter$RowCounterMapper$Counters
ROWS=374127
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0
374,127 개의 row가 있음을 확인.
직접 만든 row counter mapreduce 실행.
hadoop jar hbase-mapreduce-test.jar RowCounterJob
아래와 같이 동일한 결과 출력.
23/06/10 19:40:03 INFO mapreduce.Job: map 87% reduce 0%
23/06/10 19:40:04 INFO mapreduce.Job: map 94% reduce 0%
23/06/10 19:40:05 INFO mapreduce.Job: map 97% reduce 0%
23/06/10 19:40:06 INFO mapreduce.Job: map 100% reduce 0%
RowCounterMapper$Counters
ROWS=374127
File Input Format Counters
Bytes Read=0
File Output Format Counters
Bytes Written=0