- Authors

- Name
- Youngju Kim
- @fjvbn20031
Overview
HBase는 분산처리를 위해 하나의 Table을 region이라는 단위로 여러개로 분리해 저장하고 관리됩니다. 하나의 Region으로 시작해서, 리전의 크기가 커짐에 따라 커다란 리전은 자동으로 Split되고 2개의 region으로 분리됩니다. 그런데, 이 split 하는 과정에서 많은 cost가 들게 됩니다. 따라서 초기 Data가 많다고 판단되면, 테이블 생성시 리전을 미리 분할해 놓은 것이 Cluster에 부하를 덜 수 있습니다.
그렇다면 어떤 기준으로 Table을 split하면 좋을까요?. 아마 정답은 row-key설계에 따라 달라질 것입니다. rowkey의 범위가 1xxxxxx ~ 9xxxxxx 라는 것을 미리 안다면 prefix가 1~9 인 region들로 사전분할하는 것이 좋을 것입니다.
일반적인 상황에서 많이 사용되는 rowkey 패턴에도 범용적으로 사용할 수 있는 방법 3가지를 소개해드리겠습니다.
PreSplit 방법
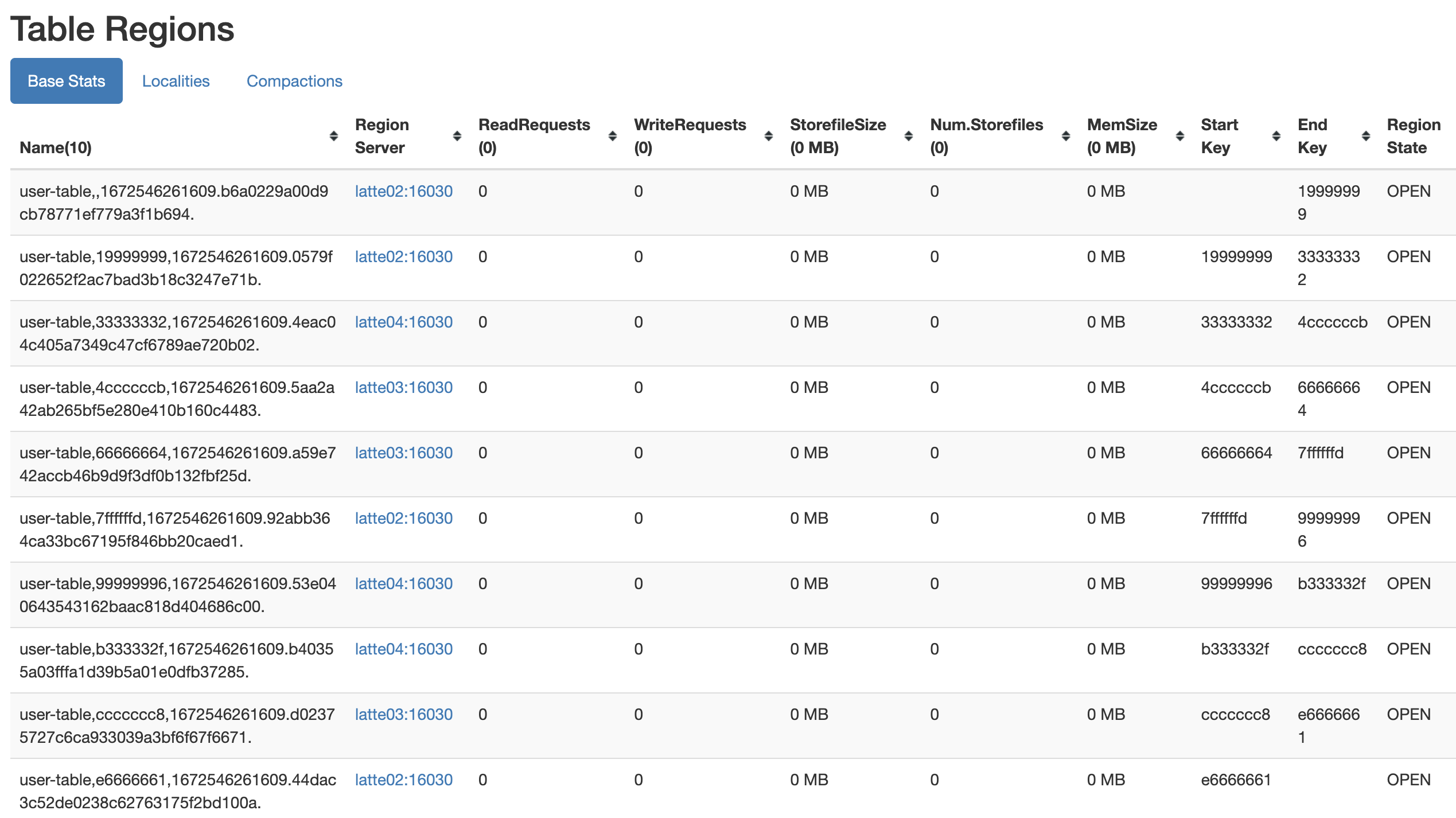
- HexStringSplit
아래와 같이 테이블 생성시 split algorithm으로 HexStringSplit 을 선택하면, region을 HexString[1-9a-z] 을 기준으로 split 하여 region을 생성합니다.
create 'user-table', 'cf', {NUMREGIONS =>10, SPLITALGO => 'HexStringSplit'}
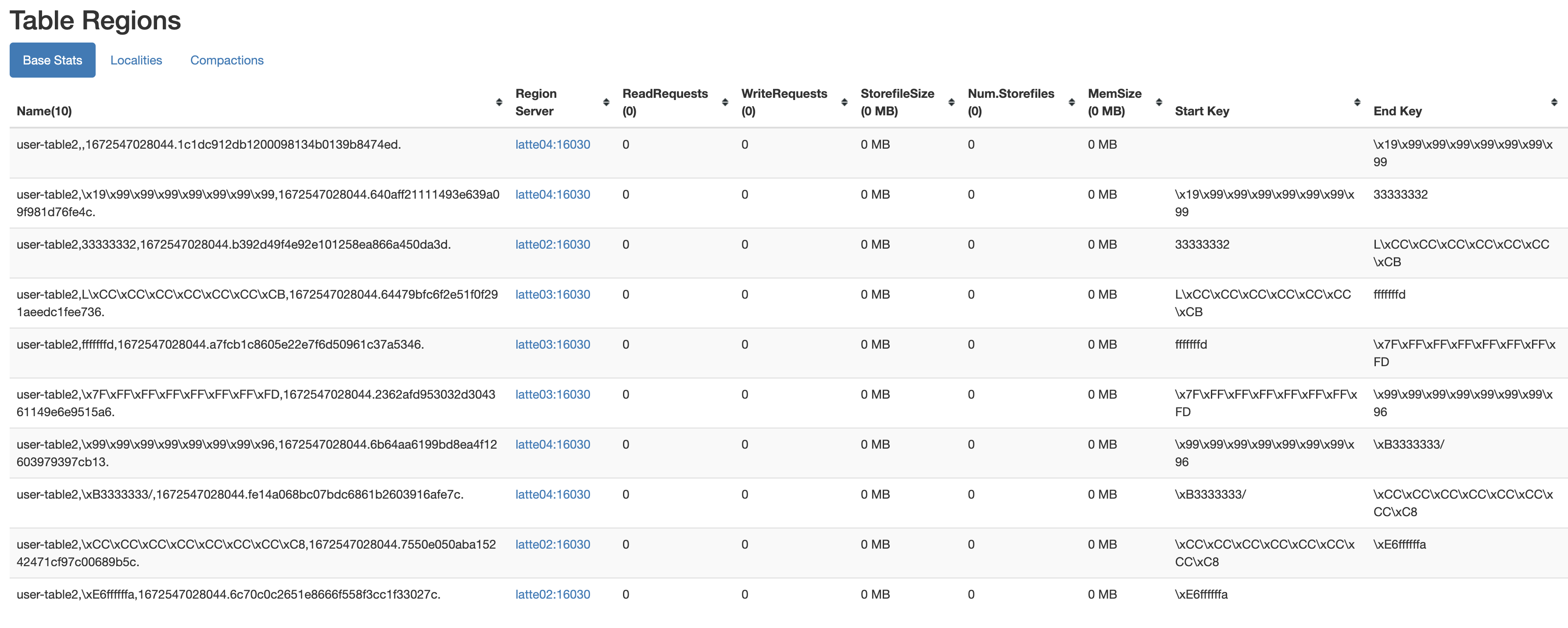
- UniformSplit
UniformSplit option도 존재합니다. table을 random bytes keys 로 분할하는 방식이고 region은 아래와 같이 생성됩니다.
create 'user-table2', 'cf', {NUMREGIONS =>10, SPLITALGO => 'UniformSplit'}
- Custom Split
HBase에서 기본으로 제공하는 split 알고리즘 대신, split 함수를 설정하여 이 대로 region을 사전분할 하는 것도 가능합니다.
저는 주로
예를 들어, 데이터가 모두 user#xxxx 라는 rowkey를 가지고 있어서 user# 이라는 prefix를 앞에 붙여야할 때 hbase shell에서 아래와 같이 테이블을 생성할 수 있습니다.
n_splits = 10
create 'usertable', 'family', {SPLITS => (1..n_splits).map {|i| "user#{1000+i*(9999-1000)/n_splits}"}}
Reference
이상으로 HBase Table을 presplit 하는 방법 3가지에 대해서 알아보는 posting을 마치겠습니다.