- Authors

- Name
- Youngju Kim
- @fjvbn20031
HDFS 아키텍쳐
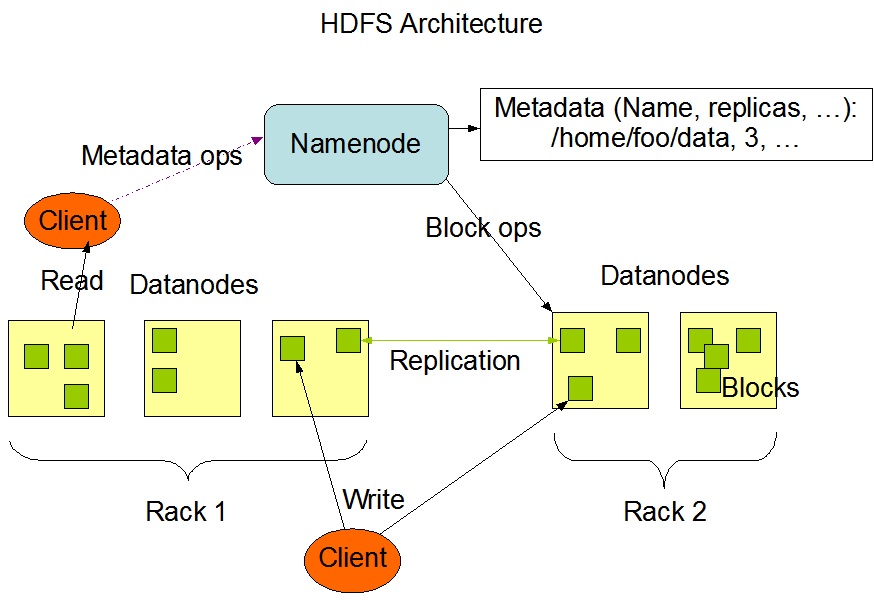
HDFS의 아키텍처는 크게 위의 그림처럼 HDFS는 파일시스템의 메타 정보를 저장하는 네임노드와 실제 데이터를 저장하는 데이터 노드로 구분할 수 있 다.블록단위로 나뉘어진 데이터들은 worker 노드에 상주하는 데이터노드라 불리는 프로세스에 의해서 관리가 되고, 이 데이터블록이 어디에 있는지 어떻게 복제되어 있는지는 Namenode에 저장되어있는 것이다. Client는 데이터를 조회하기 위해서, 반드시 Namenode에 접근하여 Block의 위치 정보를 얻어온 뒤에 Data Node로 접근해야한다.
네임노드 (Name Node)
- fsimage: 블록 정보가 담긴 메타데이터는 실시간성을 보장하기 위해 네임노드의 메모리에 저장되는데, 영속성을 위해 이를 주기적으로 스냅샷 형태의 파일로 만들어 저장한다. 이를 fs image라고 부른다.
- edit log: 가장 최신의 fsimage로 부터 현재까지의 변경사항에 대한 정보를 보관한다.
- 데이터 노드 모니터링: 데이터노드는 자신의 상태를 나타내는 Heart Beat를 Namenode로 보내고, 정해진 시간동안 Heart Beat가 없다면 해당 데이터노드를 dead node로 생각합니다.
- 복제본 관리: 데이터 노드들은 언제나 Down될 수 있기에 pipeline으로 구성된 여러개의 데이터노드들에 자신의 블록의 복사본을 복제(Replication)하도록 설정되어있다. 기본 setting값은 3이고 Rack 전체가 down되었을 때에도 데이터 유실을 막기 위해서 다른 Rack awareness를 반영하여 모든 Copy block을 하나의 Rack에 저장하는 것은 피하도록 설정되어있다.
- 접근 제어: 네임노드에 접근하는 사용자 or 그룹 정보를 기반으로 파일과 디렉터리에 대한 접근을 관리합니다.
데이터 노드(Data Node)
-
데이터 저장: Datanode는 HDFS의 실제 데이터 블록을 저장합니다. 클라이언트 또는 다른 데이터 노드로부터 데이터를 수신하여 로컬 파일 시스템에 저장하고, 필요할 때 해당 데이터를 읽어 전송합니다.
-
데이터 복제: HDFS는 내결함성을 보장하기 위해 각 데이터 블록을 여러 Datanode에 복제합니다. Namenode의 지시에 따라 Datanode는 다른 Datanode로 데이터 블록을 복제하거나, 다른 Datanode에서 데이터 블록을 받아 저장합니다.
-
하트비트 및 블록 리포트: Datanode는 주기적으로 Namenode에 "하트비트" 메시지를 전송하여 자신의 상태와 용량을 보고합니다. 또한, 일정한 간격으로 자신이 보유한 모든 데이터 블록의 목록인 "블록 리포트"를 Namenode에 전송합니다.
-
데이터 검증: Datanode는 주기적으로 저장된 데이터 블록을 검사하여 데이터의 무결성을 확인합니다. 이러한 검사를 통해 데이터 오류나 손상을 감지하고 조치를 취할 수 있습니다.
-
클라이언트 요청 처리: 클라이언트가 데이터를 읽거나 쓰기를 요청할 경우, Datanode는 해당 요청을 처리하여 데이터를 전송하거나 수신합니다.
-
삭제 및 재배치: Namenode의 지시에 따라, Datanode는 데이터 블록을 삭제하거나 다른 Datanode로 이동시킬 수 있습니다. 이는 저장 공간의 효율적인 활용 및 복제 팩터 요구사항을 충족하기 위한 작업입니다.
-
블록 복구: 블록이 손상되거나 접근 불가능한 경우, Datanode는 다른 Datanode의 복제본으로부터 해당 블록을 복구할 수 있습니다.